") 公式 其中xi为第i个人的收入,为平均收入,N为人口数量。加总符号中的第一项可以理解为个人在总收入中所占的比例,第二项为该个人相对于均值的收入。如果每一个人都有相同的收入,即等于均值,则指数为零。如果某个个人拥有所有的收入,则指数为lnN。
公式 其中xi为第i个人的收入,为平均收入,N为人口数量。加总符号中的第一项可以理解为个人在总收入中所占的比例,第二项为该个人相对于均值的收入。如果每一个人都有相同的收入,即等于均值,则指数为零。如果某个个人拥有所有的收入,则指数为lnN。
戴尔指数导自Claude Shannon的信息熵测度。设T为戴尔指数,S为Shannon的测度,则有
T = ln(N) − S
Shannon根据事件发生概率导出的其熵测度。它可以用戴尔系数解释为自某个特定个人处随机取得一块钱的概率。并与其第一项,即总收入中个人所占份额相同。
可分解性 戴尔指数的一个优点是它是某个子群体中不平等的加权和。例如,美国国内的不平等就是每个州的不平等的加权和,由该州收入相对于国家总收入的比值来加权。
如果人口被划分为m个子群体,sk 为群体k 的收入比例,Tk为该子群体的戴尔指数,而 为子群体 k的平均收入,则戴尔指数为
") 公式 因此,我们可以说某个特定群体给总体“贡献了”一定数量的不平等。
公式 因此,我们可以说某个特定群体给总体“贡献了”一定数量的不平等。
另外一个被广泛使用的不平等度量为基尼系数,该系数对于很多人来说由于基于劳伦茨曲线而非常直观。但是它却没有戴尔指数来得容易分解
 刘霆龙12.10黄金走势空头能否延续
刘霆龙12.10黄金走势空头能否延续 元宇宙到底是什么?这十点看完就明白了
元宇宙到底是什么?这十点看完就明白了 蚂蚁链“粉丝粒”,这会是全球最大NFT交
蚂蚁链“粉丝粒”,这会是全球最大NFT交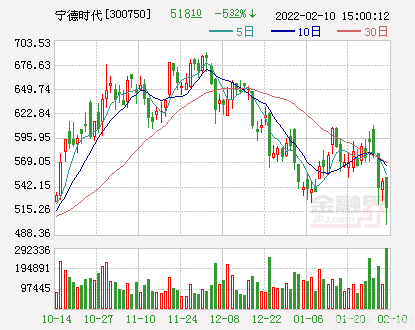 宁德时代股民年后户均亏损超百万
宁德时代股民年后户均亏损超百万 如何成为一名顶尖投资人?五点拿走不谢
如何成为一名顶尖投资人?五点拿走不谢