K-L信息量法是本世纪中叶,由Kull-back和Leibler提出,用以判定两个概率分布的接近程度。其原理是以基准序列为理论分布,备选指标为样本分布,不断变化备选指标与基准序列时差,计算K-L信息量。K-L信息量最小时对应的时差数确定为备选指标的最终时差。
对于偶然的带有随机性的现象,通常可以认为是服从某一概率分布的随机变量的一些实现值。如果已知(或假设)真正的概率分布,而希望估计我们选择的概率模型与这一真的概率分布相近似的程度,从而估计模型的好坏,就需要一个度量,这就是Kullback-Leibler信息量,即K-L信息量。
在实际的应用中,是以一个重要的,能够敏感的反映当前经济活动的经济指标作为基准指标。对于每个选取的经济指标相对于基准指标前后移动若干个月,计算K-L信息量的值。K-L信息量越小,说明真实概率分布与模型概率分布越接近,对应的移动月数就是该指标的延迟月数。
-
相关文章
 刘霆龙12.10黄金走势空头能否延续
刘霆龙12.10黄金走势空头能否延续 元宇宙到底是什么?这十点看完就明白了
元宇宙到底是什么?这十点看完就明白了 蚂蚁链“粉丝粒”,这会是全球最大NFT交
蚂蚁链“粉丝粒”,这会是全球最大NFT交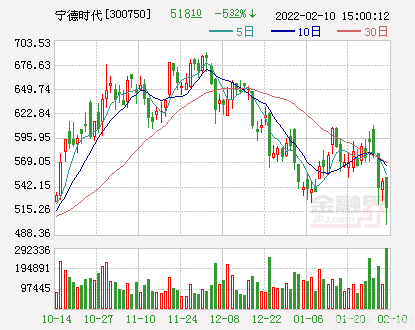 宁德时代股民年后户均亏损超百万
宁德时代股民年后户均亏损超百万 如何成为一名顶尖投资人?五点拿走不谢
如何成为一名顶尖投资人?五点拿走不谢